主要ブログの更新情報をお知らせ。最近の投稿
他の記事も多数掲載しています。
詳しくは上記のリンク先で、閲覧をどうぞ。

SEO対策・WEBサイト制作なとインターネットからの集客ならお任せ
他の記事も多数掲載しています。
詳しくは上記のリンク先で、閲覧をどうぞ。
他の記事も多数掲載しています。
詳しくは上記のリンク先で、閲覧をどうぞ。
本日テレビで下記のロボット動画を見た。
まずはご覧ください。
いやあ、すごいですねえ。
ついにロボットもここまで来ましたかと。
ただ、これはこれですごいことなんですが、プログラマー目線で言えば、決められた動きを追求してプログラミングするのは時間と根性さえあれば、いつかは達成できるかと。
この手のロボットの需要というのは、外界の動きに対して、次にどう動くのかが重要な訳で、そういう意味ではまだまだ冷静に見れる内容だ。
これがロボットの前に人がいて攻撃してきた時に、避ける、逃げる、反撃するなどの動作をしたら、目が点になるだろう。
自動車が自動運転できるかどうかの最中で、そこまで動けるロボットは2019年9月現在では世界中探しても、まだ無いでしょうね。
たた、空中を前転して立ち上がったり、横回転して着地したりの動きは、たいしたもんだなあと感心してしまった。人間だって、ここまでの運動能力のある人はそうはいませんもの。
数十年後は対人反応型ロボット、出現しそうですねえ。
個人的には映画トランスフォーマーのようなロボットを期待したいところですが。
まあ、正確に言えば、彼らはロボット型の異星人という設定ですけど。ここまでいったらすごいよなあ。
映画版の予告をどうぞ。
バンブルビー(黄色のロボット)、欲しいようなあ。
今後に期待です。
何気なくyoutubeを見ていたら、下のお勧めのところにGLOBIS知見録のビデオが出てきた。
ビジネス界を代表するキーパーソンの方々が講演を行い、それらをビデオに撮って流しているようだ。
サイトはこちら。
https://globis.jp/
動画もリンクしておきます。
サイトもそうだが、動画も結構面白いですね。
起業やらベンチャーやら、ワクワクするような題材をテーマにしているので、興味をそそられる。
動画で講演している方の出版している本なども、かつて読んだことがあるが、細かいエピソードなどは省略されていることが多く、そのあたりの雑ネタを話してくれるので、つい聞き入ってしまう。
本の場合は活字で残るので、なかなか書けなかったり、書いてから後で削除することもあるのだろう。
講演の場合は本音が聞けたりするので、本にはない面白さがある。
終わってからの質疑応答などもあり、ここでも講演者の戦略だったり、方向性などが垣間見えるので興味深い。
お勧めですね。
さて、最近のyoutubeは随分充実してきた印象を受ける。
かつては小学生向けのものが多くて見向きもしなかったが、最近はテレビよりも面白いものが増えてきた。
まさに見たい時にいつでも見れるので、これからはテレビもデンと構えてはいられないだろう。
最近は、テレビを付けて、各チャンネルを見て、つまらんなあと思えばすぐにyoutubeやらアベマTV、アマゾンprimeやらに変えてしまう。
これら動画系の最大のメリットは、見たい番組をいつでも好きな時に選べるということだろう。
関東の地上波だと、NHKと民法で7つ位の選択しかできないが、動画系は細かい映画なんかも入れたらほぼ無数にあるといっていい。
選ぶのが面倒説もあるが、そんな時は、適当なyoutubeを流しておけばよい。
便利な時代になってきましたなあ。
yoloという画像検出システムをご存知でしょうか。
画像や動画から特定の人物や動物、モノを判別してバウンディングボックスと呼ばれる四角い枠で囲うものです。
百聞は一見にしかず。
下記がyoloで検出された画像です。

こういった画像、たまに見かけますよね。
先日、トムクルーズのスパイ映画、ミッション・イン〜で登場したある男が瞳の中に特殊コンタクトをすると、
そこから見える画像を瞬時に判断して、自分の持っているスマホに、今見えている人物が誰なのかを表示するといった類のシーンがありました。
確かリアルでも似たようなシステムがあったなあと。で、このyoloのご紹介です。
さて、yoloも画像系のAIをやっているとちょこちょこ名前が出てくる代物で、2019年1月現在でV3まで進化しています。
そこで、今回はこのyoloV3をkerasとtensorflow使って、画像検出をしてみようかと。
また、静止画像だけでなく、動画でも検出してみようと。
それでは、まずyoloのインストール。
これはgitに上がっているので、cloneしてください。
git clone https://github.com/qqwweee/keras-yolo3.git
keras-yolo3に移動して
cd keras-yolo3
学習済みのモデルをダウンロード
wget https://pjreddie.com/media/files/yolov3.weights
で、kerasで使えるようにコンバート
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
さて、いよいよ実行するわけですが、
このまま実行するとファイルを選択するコマンドfilenameが出てきません。
そこでネットで検索するといろんな方法があるようですが、
このサイトの方法が楽でした。
https://qiita.com/yoyoyo_/items/10d550b03b4b9c175d9c
で、実行します。
python yolo.py
するとfilenameを聞いてきますので、画像検知したいファイル名を入力します。
Input image filename: test.jpg
ここではtest.jpgを指定しました。
結果はこちら。

人物をpersonとして検知していますね。
この時、環境によってはopenCVがうまくハマらず、エラーが出ることがあります。
そんな時もネットで検索しながら、ご自分の環境にあった方法でopenCVを入れてください。
pythonを動かすわけですから、
Anacondaで仮想環境を構築してからやった方が、いろいろ試せていいかもです。
検知した動画も載せておきましょう。
https://kk.dmacs.net/blo/douga/yoloDouga001.mp4
これは近隣施設での何かのスポーツ大会での開会式の様子です。
これだけの人数が集合すると、グラウンド内の選手の近辺は、物体が小さいせいもあり大雑把な画像検知ですね。しかし、手前に表示されている人物はしっかりと検知しています。
動画でこれだけの量を瞬時に検知できるとは。
yoloってのは、なかなかのシステムではないでしょうか。
後ほど、もう少し大き目の人物動画で検証してみたいと思っています。
今回はここまで。
******************
こういった画像検出システムに興味がある、AIをビジネスに取り入れたい、などを希望する方はご連絡ください。
>>> 本サイトのTOPはこちら。
********************
さて、今回は一休み休憩のubuntuネタだ。
今まで、ubuntu16.10を使っていたのだが、ロングサポート版の18.04LTSにバージョンアップすることにした。
とは言ってもすでに16.10はサポート終了しているので、定番の
sudo apt-get upgradeコマンドは使えない。
いろいろネットで調べたところ、
16.10→ 17.10→ 18.04へのアップデートなら可能のようだ。
さて、実際にやってみたのだが、16.10→ 17.10は問題なく終了。
お次の17.10→ 18.04のところで引っかかった。
17.10もサポートが終了しているので、上記で調べたネット情報がうまく使えない。
おまけにwindowsとubuntuのダブルOSが入っているので、なかなか思うようにいかない。
そこで、うまくいった16.10→ 17.10のコマンドを読み替えて、18.04にも適用させてみた。
これが結果オーライ。
これでOKと思いつつ、rebootしてみるとモニターには真っ暗画面が。
こいつもいろいろ調べたところ、windowsの起動を犠牲にすれば、とりあえず動くようだと判明。
もう少し詳しく調べればいろんな方法もあったと思うが、時間もない上、当面このマシンでwinを動かす予定はないので、とりあえずやってみた。
すると問題なく画面上に新規アップデートされたubuntu18.04LTSが起動。
やれやれ。
これでしばらくGPU搭載の新18.04にフル稼働してもらえそうだ。
こんにちは。株式会社マックスネット 人工知能・AI開発チームのIsoです。
今回はTensorFlowとKerasを使って、MNISTの手描き文字認識をやってみましょう。
**********
さて今回はTensorFlowとKerasを使ってMNISTという手描き文字認識をやってみたい。
ちなみにMNISTとは6万件の学習データセットと1万件の評価データセットが含まれており、学習データセットには正解ラベルも付与されている。
手描きで書かれた8という数字には、ラベルとして8が付いているといった具合だ。
このMNISTってやつは、プログラミングのHello worldみたいなもので、機械学習をやると必ず一度は通る道になっている。
さて、Kerasには始めからMNISTのデータセットを読み込み、学習データと評価データに分ける機能も組み込まれている。
そのため、こういったテストの類は非常に使いやすい。
ちなみに、TensorFlowとKerasのインストール方法は、詳しく書かれたサイトがたくさんあるので、
「TensorFlow インストール」 「Keras インストール」などで検索をかけてほしい。
それではインストールしたと仮定して、MNIST認識のコードはこちら。
下記コードを適当な名前で保存して(ここでは test_mnist.py)、python3で実行する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from keras.datasets import mnist from keras import models from keras import layers from keras.utils import to_categorical # mnistをトレーニング用とテスト用に分ける (train_images, train_labels), (test_images, test_labels) = mnist.load_data() # セッティング model01 = models.Sequential() model01.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,))) model01.add(layers.Dense(10, activation='softmax')) # コンパイル model01.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy']) # データを扱いやすいように変換する train_images = train_images.reshape((60000, 28 * 28)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28 * 28)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) # 訓練開始 model01.fit(train_images, train_labels, epochs=5, batch_size=128) # 評価してみる test_loss, test_acc = model01.evaluate(test_images, test_labels) print('acc:', test_acc) |
ざっくりとしたコメントを書いておいたのでご参考までに。
さて、では実行をしてみよう。
$ python test_mnist.py
(環境によっては、
$ python3 test_mnist.py )
どうでしょう。
$ acc: 0.9761
正解率97パーセント超えなので、まずまずといったところ。
このパーセンテージだと人間を超えた感じですね。
実行時の動画はこちら↓
TensorFlowとKerasのコンビは、kaggleコンペなどでもよく使われているセットなので、この機会にマスターしておきましょう。
こんにちは。株式会社マックスネット 人工知能・AI開発チームのIsoです。
今回は入門編からやや飛んで、強化学習にディープラーニングをプラスした「深層強化学習」の環境構築をしてみましょう。
**********
さて、今回はWindows環境で深層強化学習の環境を作るだ。
ディープラーニングを学習するのに最適な環境は、専用のubuntuマシンを作って、その中で動かしていく方法だ。
できれば、CPUではなくGPU。
ただ、簡単なコードであれば、多少時間はかかるが、CPUでも問題なく動くことが多いので、予算の少ない方やお試しで学んでみたい方にはCPU搭載マシンでも大丈夫だろう。
CPUマシンでいくのなら、昨今のPCスペックの増加により、あるOSの上に仮想環境を作って、その中でubuntuを回す方法でも十分に対処できる。
そこで、今回はwinマシンに仮想環境を作り、そこにubuntuを入れて、ゲームなどを自動で学習する深層強化学習の環境構築をしてみたい。
まず用意するのはWindowsパソコンの64ビット。
32ビットだとディープラーニングのフレームワークであるTensorFlowや Chainerなどを動かすのに手間がかかるので、ここは素直に64ビットマシンを用意しよう。
そして、仮想化ソフトはvirtialBox、VMwareなどの有名どころのどちらかを用意する。
今回はVMwareを使用。
最新のバージョン14だとubuntu16のインストール時に画面が乱れてしまい、先に進むのに手間がかかりそうだったので、VMwareのバージョン12を選択して入れてみた。
まずOSであるubuntu16.04を公式サイトよりダウンロードして、パソコンのCドライブ辺りに置いておく。
続いて、仮想化ソフトのVMwareをインストール。
ソフトのインストールが終わったら、ubntu16.04を指定して、OSのインストールを行う。
終了後にubuntuを起動してみよう。
VMwareを起動して、「仮想マシンの再生」をクリック。
すると、下記のようなubuntuのデスクトップ画面が現れる。
この画面上で、Ctrl + Alt + T の同時押しをする。
すると、真っ黒のコンソール画面が現れるので、ここに各種コマンドを入れて進行していく。
まずpwdを打ち込んでみよう。ubuntu上での、今いる階層がわかる。
/home/ユーザ名
が表示されるはずだ。
お次に簡単なコマンドを、それぞれ入力してみよう。
mkdir
新しいディレクトリィを作る
mkdir test1
カレントディレクトリィにtest1フォルダができる。
cd test1
test1フォルダの中に移動する。
ls
フォルダの中のファイルなどを表示する。
ls -al
上記の内容を更に細かく表示。
vi sample.txt
sample.txtという名前のテキストファイルを作る。
このviとは、Linux系では有名なテキストを編集するソフトで、独特な編集コマンドがある。
詳しくは「vi 使い方」などで検索するべし。
cat sample.txt
先ほど作ったsample.txtの内容のみを表示する。編集はできないので、中身を見たい時だけ安心して見れる。
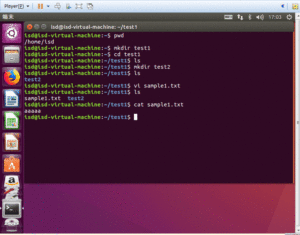
この辺のコマンドは結構頻繁に使う。
他にもいろいろなコマンドがあるので、ネットで検索しながら使ってみてほしい。
続きは次回へ。
こんにちは。株式会社マックスネット 人工知能・AI開発チームのIsoです。
今回はディープラーニングのニューラルネットワークを実装してみましょう。
**********
さて、今回はニューラルネットワークの順方向での最初の部分を実装してみよう。
まずはお決まりのニューラルネットワークの参照図です。
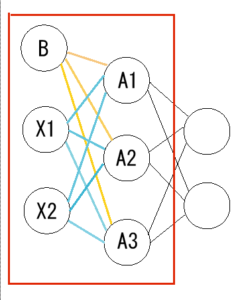
上記画像の赤枠の中を実装します。
x1とx2から出ている水色の線は「重み」を表しています。
これをW1とします。
また、オレンジの線はバイアスから出ているもので、これをB1とします。
Xからの入力値を2層目で受け取り、入力値と重みを乗じたものの総和を取り、バイアスを加えて、シグモイド関数を通して出力する。
この部分をpythonで実装してみましょう。
では、pythonコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#シグモイド関数 def sigmoid(x): return 1 / (1 + np.exp(-x)) # Xに入力値を入れる X = np.array([1.0,2.0]) # 重みに値を入れる W1 = np.array([[0.1,0.3,0.5],[0.2,0.4,0.6]]) # バイアスに値を入れる B1 = np.array([0.2,0.3,0.4]) # Xと重みの内積を出して、バイアスを加える A = np.dot(X,W1)+B1 # Aをシグモイド関数に通す Z = sigmoid(A) |
どうでしょう。
上記を繰り返していけば、何層にも渡って、順方向のニューラルネットワークを作ることができます。
(最終層である出力層のところは、関数を通さずに、そのまま出力することが多いです。ここら辺はまた後ほど)
まずは上記のコードをよく読んで、ニューラルネットワークの基礎を習得しましょう。
こんにちは。株式会社マックスネット 人工知能・AI開発チームのIsoです。
今回はディープラーニングの画像処理に使う、手元の画像データから顔認識をして、切り出す作業をやってみましょう。
*****************
さて、今回はOpenCVで顔画像を切り取ってみよう。
以前のブログでOpenCVで顔認識のpythonコードを書いてみたが、今回は描画された矩形の通りに顔画像を切り出してみたい。
切り出す画像はこちら。
画像処理のコードを書いている人にはおなじみのレナさん。

まずpythonコードはこちら。
わかりやすいように、行数を減らして最低限にしてみた。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# -*- coding: utf-8 -*- import cv2 #読み込む画像 in_jpg = "./lena.jpg" #切り取って保存する画像名 out_jpg = "./lenaCut001.jpg" #画像を読み込み image1 = cv2.imread(in_jpg) #グレースケールに変換 image_gs = cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY) # 「./haarcascade_frontalface_alt.xml」をカレントディレクトリィに置くと確実 cascade = cv2.CascadeClassifier("./haarcascade_frontalface_alt.xml") #引数についてはcascade.detectMultiScaleで検索 face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=3) #ここで切り出し if len(face_list) > 0: for rect in face_list: image_cut = image1[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]] else: print("no face") #切り出した画像を保存 cv2.imwrite(out_jpg, image_cut) |
大筋で処理手順を書いてみると、
1, 画像を読み込み
2, グレースケールに変換(処理を軽くするため)
3, カスケード分類器にかける
4, 顔認識できた矩形を、カラー画像の方で切り取る
5, 切り取った画像を保存する
一般的には最後にMatplotlibなどを使って、画像を表示させることが多いのだが、AmazonのAWSなどを使っていると、遠隔で操作しているので、画像の表示作業が面倒になる。
そこで、画像を一旦保存して、その画像を手元のPCにダウンロードし、表示させる手順を想定している。
では、上記のコードを適当な名前で (testGazou.py) 保存して実行してみよう。
$ python testGazou.py
実行後、保存されたlenaCut001.jpgをダウンロードして、表示してみる。

どうでしょうか。見事に表示されましたか。
こういった画像を大量のデータにして、ディープラーニングを動かすわけですね。